Workshop Exercise - Review Pre-upgrade Reports
Table of Contents
Objectives
- Understand the different options for managing Leapp pre-upgrade reports
- Use the RHEL Web Console to review the reports we generated
- Learn how to filter pre-upgrade report entries
- Embrace failure!
Guide
Step 1 - Managing Leapp Pre-upgrade Results
In the previous exercise, we used a playbook job template to generate a Leapp pre-upgrade report on each of our three tier app servers. Now we need to review the findings listed in those reports. There are a number of different ways that we can access the reports. Let’s review these and consider the pros and cons:
-
If we we’re using the Leapp framework to manually upgrade just a single RHEL host, we could simply get to a shell prompt on the host and look at the local report file output. In Exercise 1.1, Step 2, we learned how to open an ssh session to one of our three tier app servers. Follow those steps and after logging in, use this command to review the local Leapp pre-upgrade report file:
less /var/log/leapp/leapp-report.txtThis is a “quick and dirty” way to review the report, but doesn’t scale if you need to review reports for a large number of hosts.
Note
Use the up and down arrow keys to scroll through the file and type
qwhen you are ready to quit thelesscommand. -
If your RHEL hosts are registered to Red Hat Insights, you can see the Leapp pre-upgrade reports on your Insights console. The three tier app servers provisioned for this workshop are not registered to Insights, so we can’t demonstrate this here. Read the blog article Take the unknowns out of RHEL upgrades with Red Hat Insights to see an example of how Insights can be used to review and manage Leapp pre-upgrades.
-
RHEL includes an optional administration web console based on Cockpit that we call the RHEL Web Console. We will explore how to review the Leapp pre-upgrade reports using the RHEL Web Console in the next step of this exercise.
-
In addition to writing the plain text
leapp-report.txtfile, Leapp also generates a JSON formatleapp-report.jsonfile. This file includes the same report results as the plain text file, but in JSON format which is perfect for being ingested by log management tools like Elastic/Kibana or Splunk. Many large enterprises will push their pre-upgrade report data to one of these tools to develop their own custom dashboards that can filter reports by environment (e.g., Dev/Test/Prod), location, app ID, owning team, etc.
Step 2 - Navigating the RHEL Web Console
For this workshop, we will be using the RHEL Web Console to access the Leapp pre-upgrade reports we generated.
-
Return to the RHEL Web Console browser tab you opened from Exercise 1.1, Step 5. This is the RHEL Web Console of the AAP controller host, but we need to access our three tier app server hosts to see their pre-upgrade reports. Do this by clicking the “student@ansible-1.example.com” box in the top left corner of the RHEL Web Console to reveal the remote host menu. For example:
-
You can use the remote host menu to navigate to the web consoles of each of your three tier app servers. Try selecting one of your three tier servers now. The RHEL Web Console system overview page will show the operating system version installed. For example, this three tier app server is running RHEL7:
-
When navigating to different hosts in the RHEL Web Console, look out for the “limited access mode” warning:

If you see this, use the button to switch to administrative access mode before proceeding. A confirmation will appear like this:

-
Take some time to explore the navigation menus available with the RHEL Web Console of your different three tier app servers. Once you feel comfortable navigating around the console and switching between hosts, move on to the next step where we will look at our first pre-upgrade report.
Step 3 - Review Leapp Pre-upgrade Report of RHEL7 Host
Now let’s take a look at the report from one of our RHEL7 hosts.
-
Navigate to the RHEL Web Console remote host menu and click on
node1from your RHEL7 three tier app servers. Verify the host you have chosen is RHEL7. Then use the main menu to navigate to Tools > Upgrade Report. This will bring up the Leapp pre-upgrade report for the selected host. For example, the report might look like this:
Note
The contents of your report may differ from the example above because of updates made to the Leapp framework and other RHEL packages released over time since this workshop was written. If you discover any differences that materially break the flow of the exercises in this workshop, kindly let us know by raising an issue here.
-
When the pre-upgrade report is generated, the Leapp framework collects system data and assesses upgradeability based on a large collection of checks. When any of these checks uncovers a potential risk, it is recorded as a finding in the report. These findings are listed in order from highest risk to lowest. In the report for our RHEL7 three tier app server above, we see there are six high risk findings and two of those are inhibitor findings. Let’s start by reviewing the high risk findings that are not inhibitors.
-
At the top of the list we see the “Packages available in excluded repositories will not be installed” finding. Clicking on the finding to bring up the detailed view, we see this:
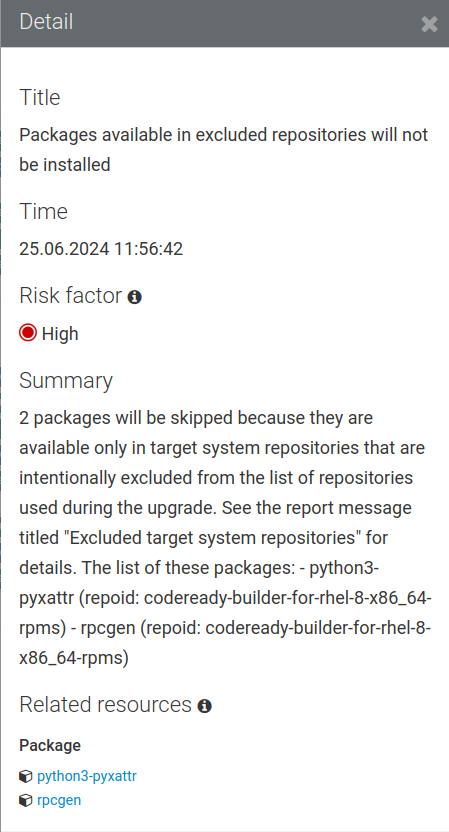
This message means the listed packages will not be upgraded as “they are available only in target system repositories that are intentionally excluded from the list of repositories used during the upgrade”.
This finding is warning that packages python3-pyxattr and rpcgen will not be upgraded but then refers to a report message titled “Excluded target system repositories” for details, with the next sentences referencing the packages and the specific repos that supply the packages:
codeready-builder-for-rhel-8-x86_64-rpms.If the packages are required for the system and needs to be upgraded, we have one of two options:
- Manually enable the relevant repository and install the packages after the in-place upgrade is finished; OR
- Execute leapp with the –enablerepo option with the relevant repository during the in-place upgrade as below
We can always add follow-up automation that takes care of the package updates post upgrade. And the second option assumes we are manually running the
leappcommand. In an upcoming exercise, we’ll explore how this option can be specified by setting a variable when submitting the upgrade playbook job. However, the Leapp engineering team most likely has good reason for excluding certain repositories during the upgrade process, so most likely we would want to proceed with option one. -
The next high risk entry on the list is the “Difference in Python versions and support in RHEL8” finding:
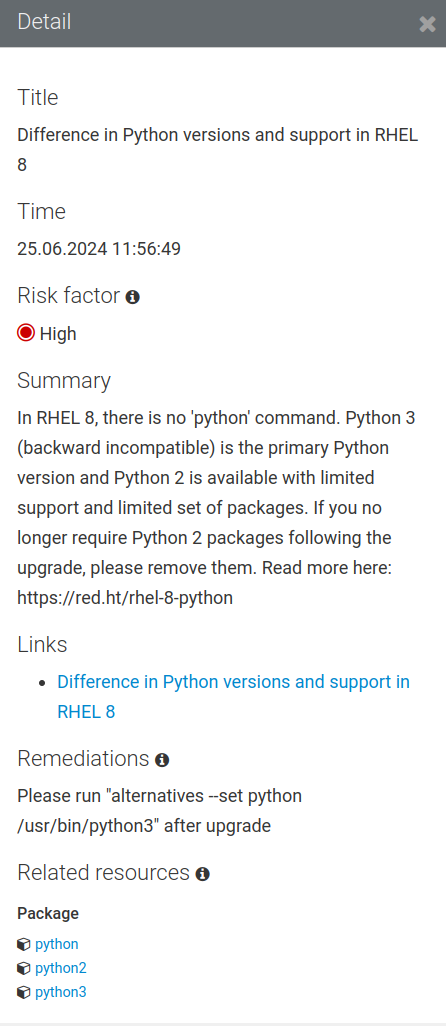
This finding could be a concern if we have any apps on our three tier server that are using the system-provided Python interpreter. Let’s assume we don’t have any of those in which case we can blissfully ignore this finding.
-
The third finding we see listed is titled “Detected modified files of the in-place upgrade tooling.” Reviewing the detailed description, the leapp utility has detected “that some files of the tooling processing the in-place upgrade have been modified. Note that such modifications can be allowed only after consultation with Red Hat”, specifically mentioning
/var/log/leapp. Theinfra.leappAnsible Validated collection that we are utilizing does work within the/var/log/leappdirectory to monitor the status of leapp utility related processes and actions, however this automation collection is directly sanctioned by Red Hat, so we can ignore this finding. -
The fourth finding we see listed has the title “GRUB2 core will be automatically updated during the upgrade.” You can see additional details for any finding by clicking on it in the list. For example, clicking on the GRUB2 core finding:

Like the finding says, no action is necessary prior to the upgrade, however, a post upgrade verification could be implemented. We’ll ignore this one for now, but make a mental note as we may revisit this with a Challenge Lab in a later exercise.
-
That leaves us with our two inhibitor findings. The first is the “Possible problems with remote login using root account” finding. You know the drill; click on the finding to review the details:
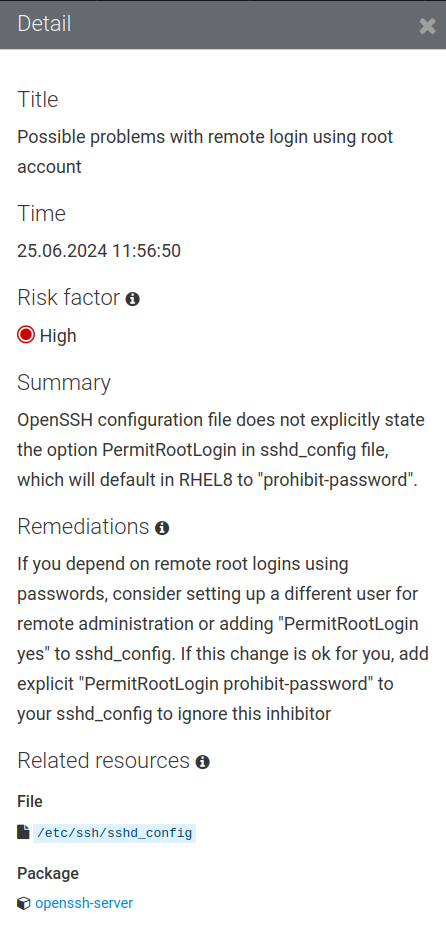
Remember that with inhibitor findings, if we don’t take action to resolve the inhibitor, the Leapp framework will block the RHEL in-place upgrade from going forward.
-
The other inhibitor is the “Missing required answers in the answer file” finding. Here are the details for this one:
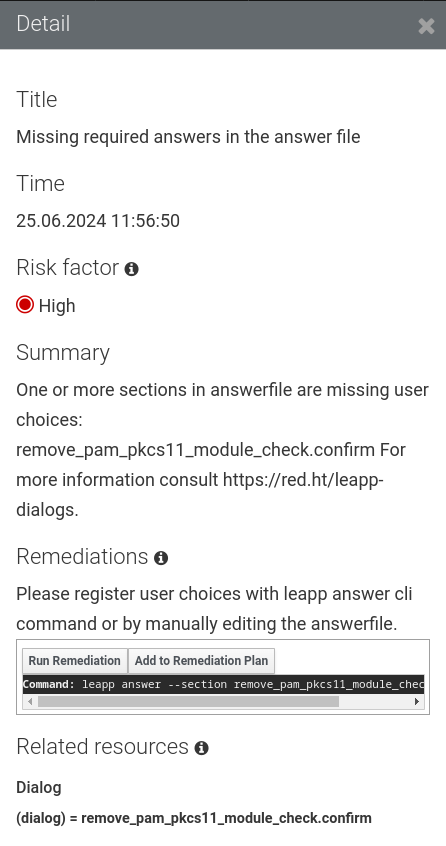
Here again, we will need to take action to remediate this finding. Don’t panic! In the next exercise, we will explore different options for automating the required remediation actions and recommendations.
Additionally, take the time to review the other medium and low risk factor findings across your systems. In this case, we are upgrading our three tier application stack. Reviewing the remainder of the medium and low risk factor findings on node1, nothing significant jumps out. Turning to node2 in the RHEL Web Console and reviewing the Upgrade Report, we see the same high risk factor findings with inhibitors that we already reviewed for node1, same for medium and low risk factors. Finally, doing the same for node3 in the RHEL Web Console and reviewing the Upgrade report, more of the same; high risk factor findings with inhibitors that we are familar with. However, moving on to review the medium and low risk factor findings, we see the following medium finding:
-
“PostgreSQL (postgresql-server) has been detected on your system”. Here are the details for this one:
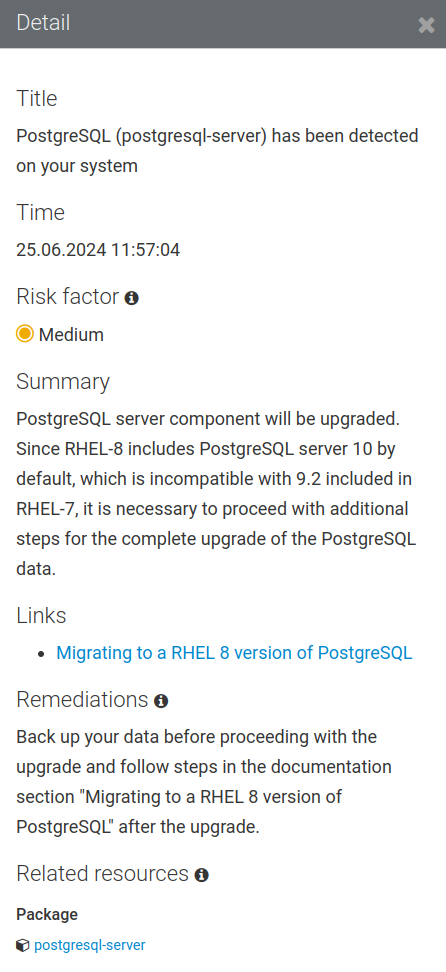
Details from the finding listing state: “PostgreSQL server component will be upgraded. Since RHEL 8 includes PostgreSQL server 10 by default, which is incompatible with 9.2 included in RHEL 7, it is necessary to proceed with additional steps for the complete upgrade of the PostgreSQL data.”
Remediation recommendation in the listing states: “Back up your data before proceeding with the upgrade and follow steps in the documentation section ‘Migrating to a RHEL 8 version of PostgreSQL’ after the upgrade.”
So in this case, we’ll need to put together some post upgrade automation to work through the updating of PostgreSQL server versions, along with migrating data.
Challenge Lab: What About Ignoring So Many High Findings?
You may be wondering why are we are mostly worrying about the inhibitor findings. What about all the other high risk findings showing up in red on the report? Red means danger! Why would we be going forward with attempting an upgrade without first resolving all the findings on the report? It’s a fair question.
Tip
Think back to the four key features that we introduced at the beginning of the workshop.
Is there a specific feature that helps with reducing risk?
Warning
Solution below!
Of course, the answer is our automated snapshot/rollback capability.
-
If any of the high risk findings listed in the pre-upgrade report ultimately leads to the upgrade failing or results in application compatibility impact, we can quickly get back to where we started by rolling back the snapshot. Before rolling back, we can debug the root cause and use the experience to understand the best way to eliminate the risk of that failure or impact happening in the future.
-
There is a concept explained quite well in the famous article Fail Fast published in IEEE Software. The article dates back to 2004, so this is hardly a new concept. Unfortunately, there is a stigma associated with failure that can lead to excessively risk-averse behavior. The most important benefit of having automated snapshots is being able to quickly revert failures. That allows us to safely adopt a fail fast and fail smart mantra.
-
Of course, there are many best practices we can follow to reduce risk. Obviously, test for application impacts by trying upgrades in your lower environments first. Any issues that can be worked out with Dev and Test servers will help you be prepared to avoid those issues in Production.
-
The high risk findings reported by the Leapp pre-upgrade report are there to make us aware of potential failure modes, but experience has shown that they are not a problem in many cases. Don’t become petrified when you see those red findings on the report. Upgrade early and often!
Conclusion
In this exercise, we learned about the different options for managing Leapp pre-upgrade reports. We used the RHEL Web Console to look at the reports we generated in the previous exercise and reviewed a number of the reported findings. In the challenge lab, we explored the importance of snapshots and learned to embrace failure.
In the next exercise, we are going to look at how to automate the remediation actions required to resolve our inhibitor findings.
Navigation